SignalForge
An intelligence pipeline that monitors news and YouTube, runs every article through a multi-stage AI workflow, and surfaces actionable B2B SaaS opportunities, each with a specific ICP, a quantified pain, an MVP breakdown, and a validation verdict.
What this is
SignalForge automates the search for B2B SaaS opportunities from news and YouTube content. The problem it solves is simple but tedious: scanning large volumes of articles every day to find the ones that suggest an unmet need in the market, a regulatory change that creates compliance overhead, a platform shift that breaks existing workflows, a cost increase that businesses are absorbing manually. Doing that by hand is slow and inconsistent. SignalForge does it automatically: ingests content, filters it, summarises it, scores it as a signal, and if the signal is strong enough, generates a structured opportunity proposal with a target customer profile, a pain statement, an MVP scope, and a validation check.
Content ingestion
Sources are defined in a YAML config file: each entry is either an RSS feed or a homepage URL to scrape. On top of that, a separate text file lists YouTube channel IDs, the system resolves each to its RSS feed automatically. When the daily run fires, a BullMQ collect queue processes every source in parallel. RSS feeds are parsed with a 24-hour age window; items without a publication date or with URLs matching a blocklist (ads, podcasts, sports, video playlists) are dropped before they enter the database. Web pages are scraped with Cheerio, links are extracted, filtered for date-pattern URLs (today/yesterday), and stored. For YouTube, if an article URL resolves to a video, the system fetches the transcript with a multi-language fallback (Spanish first, then English, then auto). Transcripts go through an intelligent segment extractor that scores each segment for pain-point density and filters for the highest-value 8,000 characters. Every article gets a SHA-1 hash on its URL for deduplication.
The pipeline
After collection, each article moves through a chain of BullMQ jobs across two queues. First, a dedupe step checks whether the article has already been processed and runs a low-SaaS-likelihood gate, if the URL path or title matches patterns like /sports/, /fashion/, /opinion/, or keywords like 'horoscope', the article is dropped before any AI call is made. Articles that pass go to a summarise step: the AI extracts a summary, a set of facts, named entities (companies, people, products, sectors), and assigns a confidence score from 0 to 1. If a high-quality YouTube transcript was found, it is used as the primary source and gets a confidence bonus. Articles below a confidence threshold (0.55 by default) are skipped before the next stage. The signal-mining step then classifies the article into a signal type, regulation, incident, platform change, cost increase, security, market shift, or other, and scores it from 0 to 100 for B2B SaaS opportunity probability. Signals below a score threshold (55) go no further. For signals that clear the bar, an opportunity-build step generates one or two structured B2B SaaS proposals. Each opportunity has a title, an ICP (target role + company size + tech stack + pain trigger), a pain statement with frequency and cost in euros, a solution in bullet form, a proposed MVP, and a list of risks. Finally, an opportunity-validate step runs a strict scoring pass against the proposal, it penalises vague ICPs, public-sector targets, dependencies on expensive datasets, and competition with major platforms; it rewards specific company sizes, named tech stacks, and quantified pain. The result is a verdict: VALID, INVALID, or NEEDS_RESEARCH.
Interfaces: web dashboard and Telegram
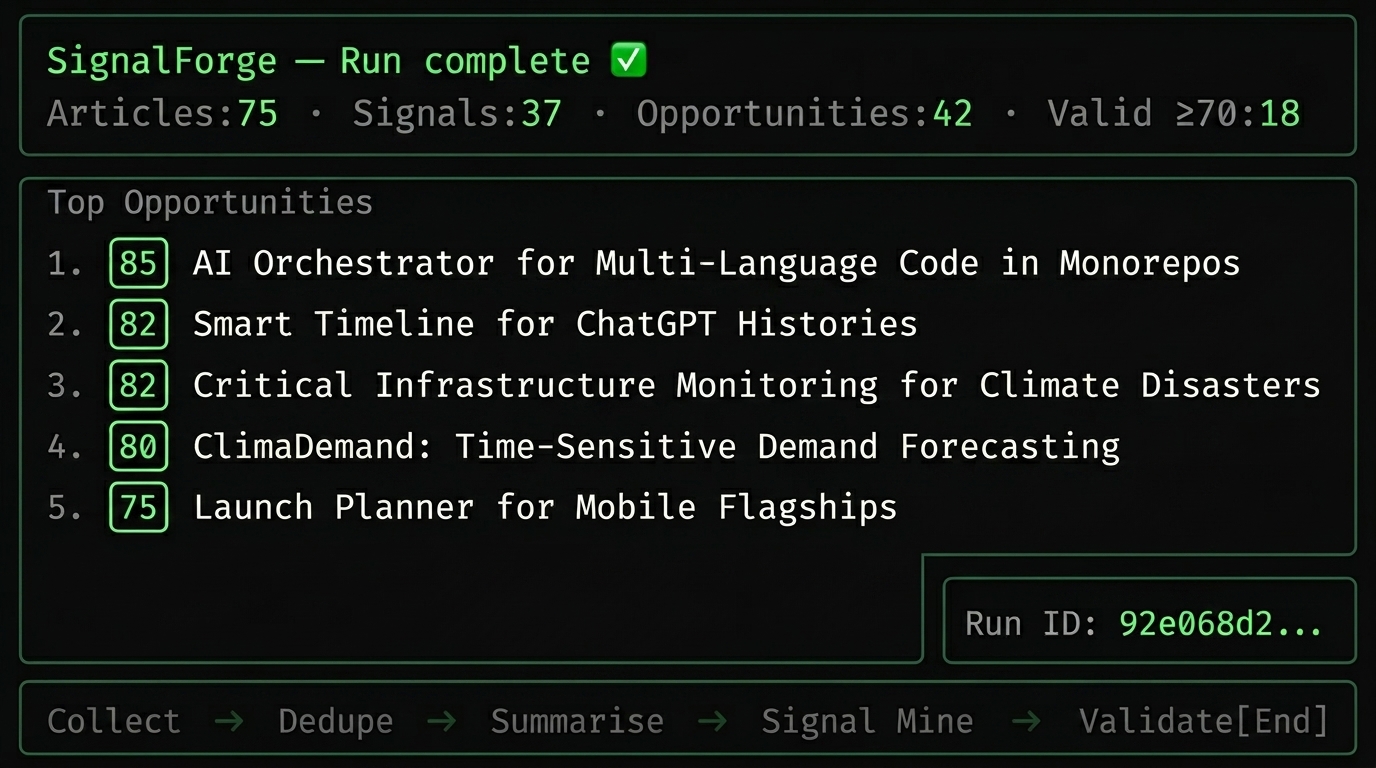
Opportunities are stored in PostgreSQL and browsable through a Next.js web app. The main view is a filterable list sorted by score, with status filters (VALID, NEEDS_RESEARCH, INVALID) and a date range. Each card shows the ICP, the pain statement, the signal type, the score, and a link to the source article. A /status endpoint exposes queue depths across all three BullMQ queues so you can see whether a run is still processing or has gone idle. The second interface is a Telegram bot that sends a summary when each run completes: total duration, articles processed, signals extracted, opportunities generated, valid count above the score threshold, and a ranked top-5 list with titles and scores. It is a push notification rather than a browsing interface, but for a daily workflow where you just want to know if the run produced anything worth reviewing, it is the right tool. Both interfaces consume the same API, so the bot and the web app always show consistent data.
What building this taught me
The most useful thing about building this was learning where AI pipelines actually break down in practice. The failure mode is almost never the AI output, it is the content quality going in. A pipeline that does not aggressively filter upstream produces a lot of AI-generated noise at the output end. The low-SaaS-likelihood gate, the confidence threshold, and the signal score gate exist because I learned that without them, the opportunity layer fills up with well-formatted nonsense derived from celebrity gossip and horoscopes that the AI summarised confidently. Getting the prompts right also took iteration: the opportunity-build prompt evolved to require a very specific ICP format (role + size + tech + pain trigger) because vague ICPs produce ideas that sound good but are impossible to act on. The scoring pattern and the structured-output discipline proved out here went directly into Property Axis's AI CRM feature, the lead scoring and pre-visit briefing systems follow the same principles.
Type
AI workflow
Built
2025
Stack